Storm运行原理探索 大数据实时处理的并行引擎
在大数据实时处理领域,Apache Storm以其高吞吐、低延迟和卓越的容错性,成为构建实时流式处理系统的核心框架之一。本文将深入探索Storm的运行原理,揭开其高效处理海量数据流的秘密。
一、核心架构与角色
Storm的架构采用主从模式,主要由以下几个核心组件构成:
- Nimbus(主节点):作为集群的“大脑”,负责资源调度、任务分配(向Supervisor分发任务)以及全局状态的监控。它本身是无状态的,通过Zookeeper进行协调与状态恢复。
- Supervisor(从节点/工作节点):负责监听并执行Nimbus分配的任务。每个Supervisor可以启动多个Worker进程来实际执行计算。
- Zookeeper:作为协调服务,负责维护Nimbus与Supervisor之间的心跳、存储集群状态、配置信息以及任务分配元数据,是保证集群高可用性的关键。
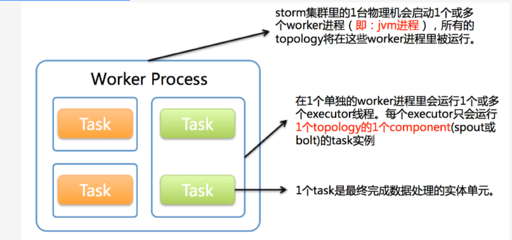
- Worker(工作进程):运行在Supervisor节点上的JVM进程,负责执行一个Topology(拓扑)的一部分。一个Worker内可以运行多个Executor。
- Executor(执行器/线程):Worker进程中的一个线程,负责运行一个或多个Task实例。
- Task(任务):实际执行数据处理的实体,是Spout或Bolt的一个实例。一个Executor线程可以串行执行多个同类型的Task。
二、数据处理模型:Topology(拓扑)
Storm应用的核心是一个被称为Topology的计算逻辑图,它定义了数据流(Stream)的转换过程。一个Topology一旦提交就会持续运行,直到被显式终止。
1. Spout(数据源):Topology的数据入口,负责从外部数据源(如Kafka、消息队列、数据库等)读取或接收数据,并以Tuple(元组)为基本单位发射到数据流中。
2. Bolt(处理单元):Topology中的所有数据处理逻辑都在Bolt中完成。Bolt可以执行过滤、聚合、连接、与数据库交互等复杂操作。Bolt既可以接收来自Spout或其他Bolt的Tuple进行处理,也可以向后续的Bolt发射新的Tuple。
Spout和Bolt通过Stream Grouping(流分组)机制进行连接,该机制定义了Tuple如何在Bolt的不同Task实例之间进行路由和分发。
三、流分组与并行度
- 流分组策略:决定了每个Tuple被发送到下游哪个Bolt的哪个Task上。常见的策略包括:
- Shuffle Grouping:随机均匀分发,保证每个Task获得大致相同数量的Tuple。
- Fields Grouping:按指定字段的值进行哈希分组,保证相同字段值的Tuple总是被送到同一个Task,是实现状态化处理(如计数、窗口)的关键。
- All Grouping:广播,将Tuple发送到所有下游Task。
- Global Grouping:全局分组,将所有Tuple发送到下游的同一个Task(通常是ID最小的那个)。
- Direct Grouping:由发射方(生产者)指定下游哪个Task来接收。
- 并行度调优:Storm的并行度是高度可配置的,从三个层面控制:
- Worker进程数:一个Topology可以跨多个Worker进程运行。
- Executor线程数:每个Spout或Bolt可以配置多个Executor线程。
- Task实例数:每个Spout或Bolt可以启动多个Task实例。Executor线程会以轮询方式执行其内部的所有Task。
通过合理配置这些参数,可以充分利用集群资源,实现水平扩展。
四、消息传递与可靠性保证
Storm提供了至少一次(at-least-once)的消息处理语义保障。其核心机制是Acker(确认器) 框架:
1. Spout发射一个Tuple时,会为其生成一个唯一的64位消息ID。
2. 该Tuple及其产生的所有衍生Tuple构成一棵“Tuple树”。
3. 系统中有一组专门的Acker Task来跟踪这些Tuple树。每当一个Tuple被成功处理,Bolt会向Acker发送一个确认消息。
4. 当整棵Tuple树都被成功处理(即树的根Tuple及其所有衍生Tuple都被确认),Acker会回调Spout的ack方法,通知该消息已被完全处理。
5. 如果处理超时(默认30秒),Acker会回调Spout的fail方法,Spout可以选择重新发射该消息。
通过这种机制,Storm确保了即使在节点故障、消息丢失等情况下,数据也不会被遗漏。
五、运行流程简述
- 提交与调度:用户将打包好的Topology Jar包提交给Nimbus。Nimbus通过Zookeeper将任务代码分发给各个Supervisor,并指示其启动特定数量的Worker。
- 初始化与执行:Worker进程启动后,会根据分配的任务创建Executor线程和Task实例,并建立网络连接(ZeroMQ或Netty)以接收和发射Tuple。
- 数据流动:Spout Task从数据源读取数据并发射Tuple。根据定义好的流分组策略,Tuple被路由到下游Bolt的对应Task中。Bolt处理完成后,可以选择发射新的Tuple到下一层,或者确认(ack)输入Tuple的处理完成。
- 监控与容错:Nimbus和Supervisor通过Zookeeper维持心跳。如果Worker进程失败,Supervisor会尝试在本机重启它。如果重启失败,Nimbus会将该Worker上的任务重新分配到集群中的其他Supervisor上。由于所有状态都保存在Zookeeper中,Nimbus本身是无状态的,因此Nimbus节点的失败可以通过重启快速恢复,而不会影响正在运行的Topology。
Storm通过其精巧的主从架构、基于Tuple的流式数据模型、灵活的并行度控制以及可靠的Acker确认机制,构建了一个高度可扩展、高可用的实时计算平台。理解其运行原理,有助于开发者更好地设计Topology、优化性能并构建稳定可靠的大数据实时处理应用。
如若转载,请注明出处:http://www.gaqyl.com/product/28.html
更新时间:2026-05-24 17:10:33